Loading...
OpenClaw ModelMesh
Intelligent LLM router
Open Source
Node.jsOpenRouter APITypeScriptZero Dependencies
The Problem
Developers pay $15-75/M tokens for Claude Opus on every message, even "what time is it?" There's no automatic way to route simple prompts to cheap models and complex ones to capable models. Companies overspend on API costs by sending simple categorization tasks to expensive frontier models.
The Solution
Intelligent LLM router with a 14-dimension weighted classifier that scores every prompt in <1ms with zero API calls. Routes to the cheapest model that can handle the task.
Key Innovation
Local classification (no API call for routing) + fallback chains + 60-80% cost savings with imperceptible latency overhead.
Visuals
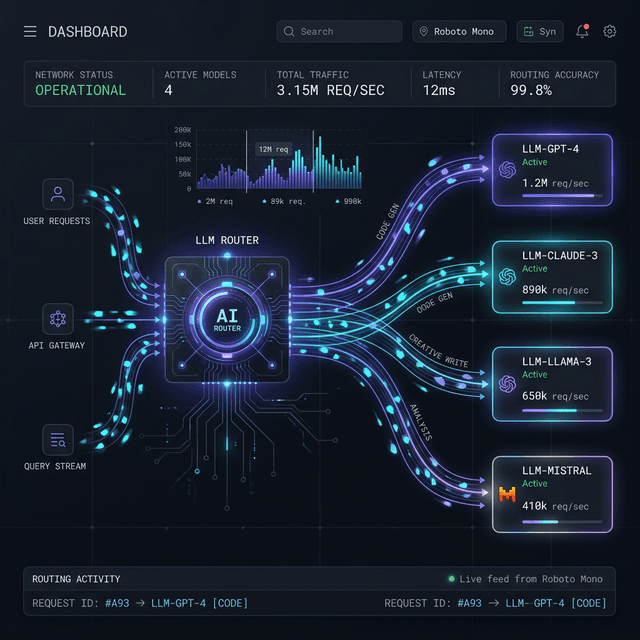
Intelligent Routing Tiers
The ModelMesh router classifies every incoming prompt and directs it to the most appropriate model based on our four-tier classification system.
| Tier | Score | Model | Cost/M Tokens | Use Case |
|---|---|---|---|---|
| SIMPLE | <0.33 | Gemini Flash | $0.10 | Quick Q&A |
| MEDIUM | 0.33-0.425 | Sonnet | $3.00 | Code gen |
| COMPLEX | 0.425-0.58 | Opus | $15.00 | Architecture |
| REASONING | ≥0.58 | Opus | $15.00 | Math proofs |
The 14 Dimensions
Our zero-shot local classifier analyzes prompts across 14 orthogonal dimensions to determine complexity in under 1ms.
Token Constraint
Weight:High
Logic Depth
Weight:High
Math/Reasoning
Weight:High
System State
Weight:Medium
Code Syntax
Weight:Medium
Context Size
Weight:Medium
Instruction Density
Weight:Medium
Creativity/Nuance
Weight:Low
Language/Locale
Weight:Low
Formatting strictness
Weight:Low
Data Extraction
Weight:Low
External Knowledge
Weight:Low
Tool Calling
Weight:Medium
Safety/Policy
Weight:High
Built With
Node.js
Foundation
OpenRouter API
Primary language
TypeScript
Key dependency
Zero Dependencies
Key dependency
Current Status
Open Source
What's Next?
Scaling infrastructure and capturing user feedback to inform the next product iteration.